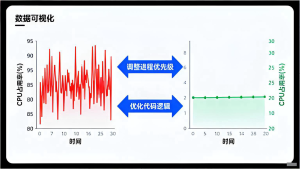


本文针对Linux服务器CPU占用率飙升的典型故障场景,提供从应急处理到根因分析的完整排查流程。通过top、perf、strace等工具的组合使用,快速定位问题进程和热点函数,并结合代码优化、配置调整和架构改进,实现CPU性能的根本性提升。
![图片[1]-Linux服务器CPU占用过高:快速定位与精准优化实战](https://blogimg.vcvcc.cc/2025/11/20251109052555317-1024x576.png?imageView2/0/format/webp/q/75)
一、紧急情况:CPU爆满的快速响应
1. 实时状态快速诊断
当收到CPU告警时,立即执行以下命令序列:
<strong>#!/bin/bash</strong>
# cpu_emergency_check.sh - CPU紧急排查脚本
echo "=== CPU紧急状态诊断 ==="
echo "诊断时间: $(date)"
# 1. 整体CPU使用情况
echo -e "\n1. 系统整体CPU使用率:"
mpstat 1 3 | tail -3
# 2. 进程级CPU占用排名
echo -e "\n2. CPU占用前10进程:"
ps aux --sort=-%cpu | head -11
# 3. 负载情况检查
echo -e "\n3. 系统负载分析:"
echo "当前负载: $(uptime | awk -F'load average:' '{print $2}')"
echo "CPU核心数: $(nproc)"
echo "运行队列: $(vmstat 1 2 | tail -1 | awk '{print $1}')"
# 4. 中断和上下文切换
echo -e "\n4. 系统中断统计:"
cat /proc/interrupts | grep -v 0 | wc -l
echo "上下文切换/秒: $(vmstat 1 2 | tail -1 | awk '{print $12}')"2. 问题进程即时处理
发现异常进程后的紧急操作:
| 问题类型 | 立即行动 | 风险等级 | 后续处理 |
|---|---|---|---|
| 未知恶意进程 | 立即kill并阻断源IP | 高危 | 安全审计、漏洞修复 |
| 业务进程异常 | 保留现场后重启 | 中危 | 代码分析、参数优化 |
| 系统进程异常 | 收集日志后重启 | 中危 | 系统更新、驱动修复 |
| 周期性峰值 | 扩容并记录模式 | 低危 | 容量规划、代码优化 |
现场保留命令:
# 保存问题进程的核心信息
pid=12345 # 替换为实际PID
cat /proc/$pid/status > /tmp/process_status_$pid.txt
cat /proc/$pid/stack > /tmp/process_stack_$pid.txt
gcore -o /tmp/core_dump $pid二、深度排查:CPU问题的根因分析
1. 性能分析工具链使用
建立完整的性能分析工作流:
<strong>#!/bin/bash</strong>
# cpu_deep_analysis.sh - CPU深度分析工具
# 检查perf是否可用
check_perf() {
if ! command -v perf > /dev/null; then
echo "安装perf工具:"
if [ -f /etc/redhat-release ]; then
yum install -y perf
else
apt-get update && apt-get install -y linux-tools-common linux-tools-generic
fi
fi
}
# 1. 系统级性能分析
system_perf_analysis() {
echo "=== 系统级性能分析 ==="
# CPU热点函数
echo -e "\n1. CPU热点函数分析:"
perf record -F 99 -a -g -- sleep 30
perf report --stdio | head -50
# 硬件事件统计
echo -e "\n2. 硬件事件统计:"
perf stat -e cycles,instructions,cache-misses,branch-misses -a sleep 10
}
# 2. 进程级深度分析
process_deep_dive() {
local pid=$1
echo "=== 进程 $pid 深度分析 ==="
# 进程状态检查
echo -e "\n1. 进程状态:"
cat /proc/$pid/status | grep -E "State|Threads|voluntary|nonvoluntary"
# 系统调用跟踪
echo -e "\n2. 系统调用统计:"
strace -c -p $pid -o /tmp/strace_$pid.txt &
strace_pid=$!
sleep 30
kill $strace_pid
cat /tmp/strace_$pid.txt
# 内存使用分析
echo -e "\n3. 内存使用模式:"
cat /proc/$pid/smaps | grep -E "Pss|Swap" | awk '{sum+=$2} END {print "总占用:", sum " KB"}'
}2. 常见CPU问题模式识别
根据症状快速定位问题类型:
| 问题症状 | 可能原因 | 验证命令 | 解决方案 |
|---|---|---|---|
| 用户CPU高,负载高 | 业务代码逻辑问题 | perf top -p <PID> | 代码优化、算法改进 |
| 系统CPU高,负载低 | 系统调用频繁 | strace -c -p <PID> | 减少系统调用、使用批量操作 |
| IO等待高,CPU空闲 | 磁盘/网络瓶颈 | iostat -x 1 | 存储优化、网络调优 |
| 软中断CPU高 | 网络处理瓶颈 | cat /proc/softirqs | 网卡多队列、中断均衡 |
| 僵尸进程增多 | 子进程管理问题 | `ps aux | grep defunct`修复进程回收逻辑 |
三、代码级优化:热点函数性能提升
1. 识别性能瓶颈代码
使用perf进行函数级分析:
# 对特定进程进行性能分析
pid=$(pgrep -f your_application)
# 生成火焰图所需数据
perf record -F 99 -p $pid -g -- sleep 60
perf script > perf_script.out
# 使用FlameGraph生成火焰图
git clone https://github.com/brendangregg/FlameGraph.git
cd FlameGraph
./stackcollapse-perf.pl ../perf_script.out | ./flamegraph.pl > ../flamegraph.svg2. 常见代码优化模式
针对识别出的热点进行优化:
| 优化场景 | 问题代码示例 | 优化后代码 | 性能提升 |
|---|---|---|---|
| 循环内的系统调用 | for(i=0;i<1000;i++){ write(fd,buf,len); } | for(i=0;i<1000;i++){ buffer_append(buf); } write(fd,buffer, total_len); | 10-100倍 |
| 字符串拼接 | str = "a" + "b" + "c" + ... | "".join(["a", "b", "c", ...]) | 3-5倍 |
| 重复计算 | 循环内重复计算相同表达式 | 预先计算,循环外存储结果 | 2-3倍 |
| 不必要的对象创建 | 循环内创建临时对象 | 对象复用、对象池 | 2-8倍 |
Java应用优化示例:
// 优化前:循环内创建对象
public void processData(List<String> data) {
for (String item : data) {
SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd");
// 处理逻辑
}
}
// 优化后:对象复用
private static final SimpleDateFormat SDF = new SimpleDateFormat("yyyy-MM-dd");
public void processData(List<String> data) {
for (String item : data) {
// 使用共享的SDF对象
}
}Python应用优化示例:
# 优化前:使用+拼接字符串
result = ""
for item in items:
result += str(item)
# 优化后:使用join
result = "".join(str(item) for item in items)四、系统级调优:内核参数优化
1. CPU调度优化配置
调整内核参数提升CPU效率:
<strong>#!/bin/bash</strong>
# cpu_scheduler_tuning.sh - CPU调度器优化
# 检查当前调度器配置
echo "当前CPU调度器配置:"
cat /sys/block/sda/queue/scheduler <strong>2</strong>>/dev/null || echo "无法获取磁盘调度器"
# 针对不同工作负载的优化建议
case $WORKLOAD_TYPE in
"web_server")
# Web服务器优化
echo "应用Web服务器优化..."
# 调整进程调度策略
echo 1 > /proc/sys/kernel/sched_child_runs_first
echo 1000000 > /proc/sys/kernel/sched_latency_ns
;;
"database")
# 数据库服务器优化
echo "应用数据库优化..."
# 降低调度粒度,提高响应性
echo 100000 > /proc/sys/kernel/sched_min_granularity_ns
;;
"compute")
# 计算密集型优化
echo "应用计算密集型优化..."
# 提高调度粒度,减少上下文切换
echo 10000000 > /proc/sys/kernel/sched_min_granularity_ns
;;
esac
# 中断均衡配置
echo "配置中断均衡..."
for irq in /proc/irq/*; do
if [ -d "$irq" ]; then
echo 1 > "$irq/smp_affinity" <strong>2</strong>>/dev/null
fi
done2. 内核参数优化表
针对高CPU场景的核心参数调整:
| 参数路径 | 默认值 | 推荐值 | 作用说明 |
|---|---|---|---|
kernel.sched_min_granularity_ns | 3000000 | 1000000 | 减少调度开销 |
kernel.sched_migration_cost_ns | 500000 | 100000 | 降低迁移成本 |
kernel.sched_autogroup_enabled | 1 | 0 | 禁用自动分组 |
vm.dirty_ratio | 20 | 10 | 减少脏页回写 |
vm.swappiness | 60 | 10 | 降低交换倾向 |
net.core.somaxconn | 128 | 1024 | 提高连接队列 |
永久生效配置:
# 编辑 /etc/sysctl.conf
echo 'kernel.sched_min_granularity_ns = 1000000' >> /etc/sysctl.conf
echo 'vm.swappiness = 10' >> /etc/sysctl.conf
echo 'net.core.somaxconn = 1024' >> /etc/sysctl.conf
sysctl -p五、应用架构优化:从根本上解决问题
1. 异步处理与队列化
将同步操作改为异步处理:
# 优化前:同步处理导致CPU等待
def process_request(request):
# CPU密集型计算
result = heavy_computation(request.data)
# IO密集型操作(阻塞CPU)
db.save(result)
return result
# 优化后:异步处理
import asyncio
from concurrent.futures import ThreadPoolExecutor
async def process_request_async(request):
# CPU计算在线程池中执行
loop = asyncio.get_event_loop()
with ThreadPoolExecutor() as executor:
result = await loop.run_in_executor(
executor, heavy_computation, request.data
)
# 异步数据库操作
await db.save_async(result)
return result2. 缓存策略优化
减少重复计算和数据库访问:
| 缓存层级 | 适用场景 | 技术选型 | 配置要点 |
|---|---|---|---|
| CPU缓存 | 热点数据访问 | 算法优化、数据局部性 | 减少缓存未命中 |
| 内存缓存 | 频繁读取数据 | Redis、Memcached | 合理设置过期时间 |
| 应用缓存 | 计算结果复用 | 本地缓存、Guava Cache | 控制内存使用 |
| 数据库缓存 | 查询结果缓存 | 查询缓存、结果集缓存 | 及时失效更新 |
多级缓存实现示例:
public class MultiLevelCache {
private final Cache<String, Object> localCache;
private final RedisTemplate redisTemplate;
public Object get(String key) {
// 1. 检查本地缓存
Object value = localCache.getIfPresent(key);
if (value != null) {
return value;
}
// 2. 检查Redis缓存
value = redisTemplate.opsForValue().get(key);
if (value != null) {
localCache.put(key, value); // 回填本地缓存
return value;
}
// 3. 从数据库加载
value = loadFromDatabase(key);
if (value != null) {
redisTemplate.opsForValue().set(key, value, Duration.ofMinutes(30));
localCache.put(key, value);
}
return value;
}
}六、监控与预防:建立长效机制
1. 实时监控告警配置
使用Prometheus + Grafana建立监控体系:
# prometheus_rules.yml
groups:
- name: cpu_alerts
rules:
- alert: HighCPUUsage
expr: 100 - (avg by (instance) (rate(node_cpu_seconds_total{mode="idle"}[5m])) * 100) > 80
for: 5m
labels:
severity: warning
annotations:
summary: "CPU使用率过高"
description: "实例 {{ $labels.instance }} CPU使用率持续5分钟超过80%"
- alert: CPUStealTime
expr: avg by (instance) (rate(node_cpu_seconds_total{mode="steal"}[5m])) * 100 > 5
for: 3m
labels:
severity: critical
annotations:
summary: "CPU被宿主机抢占"
description: "实例 {{ $labels.instance }} CPU被抢占超过5%,可能受邻宿影响"2. 性能基线建立
创建系统性能基线用于异常检测:
<strong>#!/bin/bash</strong>
# performance_baseline.sh - 性能基线采集
BASELINE_DIR="/var/log/performance_baseline"
mkdir -p $BASELINE_DIR
# 采集性能指标
collect_metrics() {
local timestamp=$(date +%Y%m%d_%H%M%S)
# CPU相关指标
mpstat 1 5 > "$BASELINE_DIR/cpu_$timestamp.log"
ps aux --sort=-%cpu | head -20 > "$BASELINE_DIR/process_cpu_$timestamp.log"
# 内存指标
free -m > "$BASELINE_DIR/memory_$timestamp.log"
# 系统负载
uptime > "$BASELINE_DIR/load_$timestamp.log"
vmstat 1 5 > "$BASELINE_DIR/vmstat_$timestamp.log"
# 网络连接
ss -s > "$BASELINE_DIR/network_$timestamp.log"
}
# 定期执行采集
while true; do
collect_metrics
# 保留最近7天的基线数据
find $BASELINE_DIR -name "*.log" -mtime +7 -delete
sleep 3600 # 每小时采集一次
done七、典型案例分析
1. 案例一:Java应用Full GC导致CPU飙升
问题现象:Java应用CPU周期性达到100%,系统负载飙升
排查过程:
# 1. 发现Java进程CPU高
ps aux | grep java
# 2. 检查GC情况
jstat -gc <pid> 1s
# 3. 分析GC日志(如果已开启)
tail -f /path/to/gc.log解决方案:
- 调整JVM参数:
-Xmx4g -Xms4g -XX:+UseG1GC -XX:MaxGCPauseMillis=200 - 优化内存使用,减少对象创建
- 增加Young区大小,减少Full GC频率
2. 案例二:MySQL查询导致CPU占用高
问题现象:数据库服务器CPU持续高位运行
排查过程:
-- 查看当前执行中的查询
SHOW PROCESSLIST;
-- 分析慢查询
SELECT * FROM information_schema.processlist
WHERE COMMAND != 'Sleep' AND TIME > 10;
-- 检查索引使用情况
EXPLAIN SELECT * FROM large_table WHERE unindexed_column = 'value';解决方案:
- 为频繁查询的字段添加索引
- 优化SQL语句,避免全表扫描
- 调整MySQL配置:
query_cache_size,innodb_buffer_pool_size - 读写分离,分散负载
总结
CPU占用过高问题的解决需要系统化的方法:
排查流程总结:
- 紧急处理:快速定位问题进程,确保系统可用性
- 深度分析:使用专业工具分析性能瓶颈
- 代码优化:针对热点函数进行算法和逻辑优化
- 系统调优:调整内核参数和系统配置
- 架构改进:从根本上优化应用架构
- 监控预防:建立完善的监控和预警机制
关键工具回顾:
top/htop– 进程级监控perf– 系统级性能分析strace– 系统调用跟踪vmstat– 系统资源统计jstat– JVM性能监控
通过上述系统化的方法,可以有效地解决Linux服务器CPU占用过高的问题,并建立预防类似问题再次发生的长效机制。
© 版权声明
THE END












暂无评论内容