


Linux系统性能故障是运维工程师日常工作中最常见的技术挑战。本文通过二十个真实生产环境案例,深度解析内存泄漏、CPU爆满、磁盘IO瓶颈等高频故障的排查方法和解决方案,提供完整的命令工具链、监控脚本和应急处理流程,帮助企业快速定位和解决系统性能问题。
![图片[1]-Linux系统性能故障排查与优化实战:内存、CPU、IO问题深度解析-Vc博客](https://blogimg.vcvcc.cc/2025/11/20251106144422552.jpg?imageView2/0/format/webp/q/75)
一、内存问题排查与优化实战
1. 内存泄漏快速定位方法
(1)问题现象识别
# 内存使用实时监控脚本
#!/bin/bash
# memory_health_check.sh
echo "====== 内存健康检查 ======"
echo "检查时间: $(date)"
# 基础内存信息
echo -e "\n1. 系统内存状态:"
free -h
# 详细内存分析
echo -e "\n2. 详细内存分布:"
cat /proc/meminfo | grep -E "MemTotal|MemFree|MemAvailable|Buffers|Cached|SwapCached"
# 进程内存排行
echo -e "\n3. 内存占用TOP10进程:"
ps aux --sort=-%mem | head -11 | awk 'BEGIN{printf "%-10s %-8s %-8s %-12s\n","进程名","PID","内存%","内存大小"}{if(NR>1)printf "%-10s %-8s %-8s %-12s\n",$11,$2,$4,$6}'
# Slab内存泄露检查
echo -e "\n4. Slab内存分析:"
echo "Slab总数: $(grep Slab /proc/meminfo | awk '{print $2}') KB"
echo "SReclaimable: $(grep SReclaimable /proc/meminfo | awk '{print $2}') KB"
# 检查内存泄漏迹象
echo -e "\n5. 内存泄漏指标:"
if [ $(grep MemAvailable /proc/meminfo | awk '{print $2}') -lt 1048576 ]; then
echo "警告: 可用内存不足1GB!"
fi
if [ $(grep SwapCached /proc/meminfo | awk '{print $2}') -gt 1048576 ]; then
echo "警告: 交换缓存超过1GB,可能存在内存压力!"
fi(2)内存泄漏进程定位
<strong>#!/bin/bash</strong>
# find_memory_leak.sh
# 设置内存增长阈值(MB)
THRESHOLD=100
INTERVAL=60
echo "开始监控内存泄漏进程,阈值: ${THRESHOLD}MB,间隔: ${INTERVAL}秒"
# 创建进程内存快照
create_snapshot() {
ps -eo pid,ppid,rss,comm --sort=-rss | awk 'NR>1{print $1","$2","$3","$4}'
}
# 比较快照,找出内存增长异常的进程
analyze_growth() {
local old_snapshot=$1
local new_snapshot=$2
while IFS=, read -r pid ppid rss comm; do
local old_rss=$(grep "^$pid," "$old_snapshot" | cut -d, -f3)
if [ -n "$old_rss" ] && [ "$rss" -gt "$old_rss" ]; then
local growth=$((rss - old_rss))
local growth_mb=$((growth / 1024))
if [ $growth_mb -ge $THRESHOLD ]; then
echo "警告: 进程 $comm(PID:$pid) 内存增长 ${growth_mb}MB"
echo "详细信息:"
ps -p $pid -o pid,ppid,rss,vsz,comm,cmd --no-headers
fi
fi
done < "$new_snapshot"
}
# 主监控循环
OLD_SNAPSHOT=$(mktemp)
create_snapshot > "$OLD_SNAPSHOT"
while true; do
sleep $INTERVAL
NEW_SNAPSHOT=$(mktemp)
create_snapshot > "$NEW_SNAPSHOT"
echo "=== $(date) 内存增长分析 ==="
analyze_growth "$OLD_SNAPSHOT" "$NEW_SNAPSHOT"
mv "$NEW_SNAPSHOT" "$OLD_SNAPSHOT"
done
# 清理临时文件
trap 'rm -f "$OLD_SNAPSHOT"' EXIT(3)Java应用内存泄漏排查
<strong>#!/bin/bash</strong>
# java_memory_leak_diagnose.sh
# 查找Java进程
JAVA_PIDS=$(ps aux | grep java | grep -v grep | awk '{print $2}')
for pid in $JAVA_PIDS; do
echo "分析Java进程: $pid"
# 获取堆内存信息
echo "堆内存使用:"
jstat -gc $pid <strong>2</strong>>/dev/null || echo "需要JDK工具支持"
# 生成堆转储(需要确认)
read -p "是否生成堆转储文件? (y/N): " -n 1 -r
echo
if [[ $REPLY =~ ^[Yy]$ ]]; then
jmap -dump:live,format=b,file=heapdump_${pid}_$(date +%Y%m%d_%H%M%S).hprof $pid
echo "堆转储文件已生成"
fi
# 检查GC情况
echo "GC统计:"
jstat -gcutil $pid <strong>2</strong>>/dev/null || echo "无法获取GC信息"
echo "----------------------------------------"
done2. 内存耗尽应急处理
(1)快速释放内存脚本
<strong>#!/bin/bash</strong>
# emergency_memory_release.sh
echo "开始紧急内存释放..."
# 1. 清理PageCache
echo "清理PageCache..."
echo 1 > /proc/sys/vm/drop_caches
# 2. 清理dentries和inodes
echo "清理dentries和inodes..."
echo 2 > /proc/sys/vm/drop_caches
# 3. 清理PageCache、dentries和inodes
echo "全面清理..."
echo 3 > /proc/sys/vm/drop_caches
# 4. 检查大内存进程
echo "检查大内存进程..."
ps aux --sort=-%mem | head -10
# 5. 检查OOM killer日志
echo "检查OOM记录..."
if dmesg | grep -i "killed process"; then
echo "发现OOM killer记录"
dmesg | grep -i "killed process" | tail -5
fi
# 6. 检查交换空间
echo "交换空间使用:"
swapon -s
# 7. 重启内存占用最高的服务(谨慎使用)
read -p "是否重启内存占用最高的进程? (y/N): " -n 1 -r
echo
if [[ $REPLY =~ ^[Yy]$ ]]; then
TOP_PROCESS=$(ps aux --sort=-%mem | head -2 | tail -1 | awk '{print $2}')
TOP_PROCESS_NAME=$(ps aux --sort=-%mem | head -2 | tail -1 | awk '{print $11}')
echo "重启进程: $TOP_PROCESS_NAME (PID: $TOP_PROCESS)"
kill -9 $TOP_PROCESS
# 这里应该添加服务重启命令
fi
echo "内存释放完成"二、CPU性能问题深度排查
1. CPU使用率爆满诊断
(1)实时CPU监控脚本
<strong>#!/bin/bash</strong>
# cpu_performance_monitor.sh
echo "====== CPU性能监控 ======"
echo "监控时间: $(date)"
# CPU整体使用率
echo -e "\n1. CPU整体使用率:"
mpstat 1 3 | tail -3
# 负载平均值
echo -e "\n2. 系统负载:"
uptime | awk -F'load average:' '{print $2}'
# 每个CPU核心使用率
echo -e "\n3. 各CPU核心使用率:"
mpstat -P ALL 1 1 | grep -v "CPU" | grep -v "平均时间"
# 进程CPU使用排行
echo -e "\n4. CPU使用TOP10进程:"
ps aux --sort=-%cpu | head -11 | awk 'BEGIN{printf "%-10s %-8s %-8s %-12s\n","进程名","PID","CPU%","状态"}{if(NR>1)printf "%-10s %-8s %-8s %-12s\n",$11,$2,$3,$8}'
# 运行队列和上下文切换
echo -e "\n5. 系统上下文切换:"
vmstat 1 3
# 中断统计
echo -e "\n6. 中断统计:"
cat /proc/interrupts | head -10(2)高CPU占用进程分析
<strong>#!/bin/bash</strong>
# high_cpu_analysis.sh
# 设置CPU阈值
CPU_THRESHOLD=50
echo "开始分析高CPU占用进程,阈值: ${CPU_THRESHOLD}%"
while true; do
echo "=== $(date) ==="
# 查找高CPU进程
HIGH_CPU_PROCESSES=$(ps aux --sort=-%cpu | awk -v threshold=$CPU_THRESHOLD 'NR>1 && $3 > threshold {print $2","$3","$11}')
if [ -n "$HIGH_CPU_PROCESSES" ]; then
echo "发现高CPU进程:"
echo "PID CPU% 进程名"
echo "$HIGH_CPU_PROCESSES" | while IFS=, read -r pid cpu name; do
printf "%-6s %-6s %s\n" "$pid" "$cpu" "$name"
# 分析进程状态
echo "进程详细状态:"
ps -p $pid -o pid,ppid,state,pcpu,pmem,comm,cmd --no-headers
# 检查进程线程
echo "线程CPU使用:"
ps -L -p $pid -o tid,pcpu,state | sort -k2 -nr | head -5
# 生成CPU性能分析(perf)
read -p "是否对进程 $pid 进行性能分析? (y/N): " -n 1 -r
echo
if [[ $REPLY =~ ^[Yy]$ ]]; then
if command -v perf >/dev/null <strong>2</strong>><strong>&1</strong>; then
perf record -g -p $pid -o perf_data_${pid}.data -- sleep 10
echo "性能数据已保存到 perf_data_${pid}.data"
else
echo "perf工具未安装"
fi
fi
echo "---"
done
else
echo "未发现超过阈值的高CPU进程"
fi
sleep 30
done(3)死循环进程检测
<strong>#!/bin/bash</strong>
# dead_loop_detector.sh
echo "死循环进程检测..."
# 检查D状态进程(不可中断睡眠)
echo "1. 检查D状态进程:"
ps -eo pid,ppid,state,comm | grep -w D
# 检查R状态且长时间运行的进程
echo -e "\n2. 检查长时间运行的R状态进程:"
ps -eo pid,ppid,state,etime,pcpu,comm | grep -w R | while read line; do
etime=$(echo $line | awk '{print $4}')
# 检查运行时间是否超过1小时
if [[ $etime == *-* ]] || [[ $etime == *:*:* ]]; then
echo "长时间运行: $line"
fi
done
# 检查内核软死锁
echo -e "\n3. 检查软死锁:"
if dmesg | grep -i "soft lockup"; then
echo "发现软死锁记录:"
dmesg | grep -i "soft lockup" | tail -3
fi
# 检查系统调用跟踪
echo -e "\n4. 高系统调用进程:"
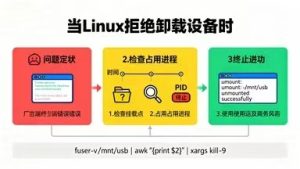
pidstat -w 1 1 | sort -k4 -nr | head -10三、磁盘IO问题排查优化
1. 磁盘性能瓶颈诊断
(1)全面IO监控脚本
<strong>#!/bin/bash</strong>
# disk_io_performance.sh
echo "====== 磁盘IO性能分析 ======"
# 1. 整体IO统计
echo -e "\n1. 系统IO统计:"
iostat -x 1 3
# 2. 设备级IO监控
echo -e "\n2. 块设备IO详情:"
for device in $(lsblk -d -o NAME | grep -v NAME); do
if [ -f /sys/block/$device/stat ]; then
read reads sectors_read writes sectors_write < /sys/block/$device/stat
echo "设备 $device: 读操作=$reads, 写操作=$writes"
fi
done
# 3. 进程IO使用排行
echo -e "\n3. 进程IO使用TOP10:"
pidstat -d 1 1 | sort -k4 -nr | head -11
# 4. 文件系统使用情况
echo -e "\n4. 文件系统使用率:"
df -h | grep -v tmpfs
# 5. Inode使用情况
echo -e "\n5. Inode使用率:"
df -i | grep -v tmpfs
# 6. 检查IO等待
echo -e "\n6. CPU IO等待:"
mpstat 1 3 | awk '/平均时间/ {getline; print "IO等待: "$6"%"}'
# 7. 高IO进程详细分析
echo -e "\n7. 高IO进程分析:"
iotop -b -n 1 -o | head -15(2)磁盘瓶颈定位工具
<strong>#!/bin/bash</strong>
# disk_bottleneck_finder.sh
# 测试磁盘读写性能
test_disk_performance() {
local test_dir=$1
local test_file="$test_dir/disk_test"
echo "测试目录: $test_dir"
# 写性能测试
echo "写性能测试:"
dd if=/dev/zero of="$test_file" bs=1M count=1024 oflag=direct <strong>2</strong>><strong>&1</strong> | tail -1
# 读性能测试
echo "读性能测试:"
dd if="$test_file" of=/dev/null bs=1M iflag=direct <strong>2</strong>><strong>&1</strong> | tail -1
# 清理测试文件
rm -f "$test_file"
}
# 检查磁盘健康状态
check_disk_health() {
echo -e "\n磁盘健康状态:"
# 检查SMART信息(需要smartmontools)
if command -v smartctl >/dev/null <strong>2</strong>><strong>&1</strong>; then
for device in $(lsblk -d -o NAME | grep -v NAME); do
if [ -e "/dev/$device" ]; then
echo "检查设备 /dev/$device:"
smartctl -H "/dev/$device" <strong>2</strong>>/dev/null | grep -E "SMART|结果" || echo "SMART不可用"
fi
done
else
echo "安装smartmontools以获取磁盘健康信息"
fi
}
# 分析IO调度器
analyze_io_scheduler() {
echo -e "\nIO调度器配置:"
for device in $(lsblk -d -o NAME | grep -v NAME); do
if [ -f "/sys/block/$device/queue/scheduler" ]; then
scheduler=$(cat "/sys/block/$device/queue/scheduler")
echo "设备 $device: $scheduler"
fi
done
}
# 检查RAID状态
check_raid_status() {
echo -e "\nRAID状态检查:"
# 检查MD RAID
if [ -f /proc/mdstat ]; then
echo "MD RAID状态:"
cat /proc/mdstat
fi
# 检查LVM
if command -v pvs >/dev/null <strong>2</strong>><strong>&1</strong>; then
echo -e "\nLVM状态:"
pvs <strong>2</strong>>/dev/null
vgs <strong>2</strong>>/dev/null
lvs <strong>2</strong>>/dev/null
fi
}
# 主执行函数
main() {
local test_dir=${1:-/tmp}
echo "开始磁盘性能分析..."
test_disk_performance "$test_dir"
check_disk_health
analyze_io_scheduler
check_raid_status
}
main "$@"2. IO性能优化方案
(1)磁盘参数调优脚本
<strong>#!/bin/bash</strong>
# disk_optimization.sh
echo "开始磁盘性能优化..."
# 根据磁盘类型优化参数
optimize_disk_params() {
local device=$1
local device_type=$2
echo "优化设备: $device (类型: $device_type)"
# 设置IO调度器
case $device_type in
"ssd")
echo "设置为SSD优化参数"
echo noop > /sys/block/$device/queue/scheduler
echo 256 > /sys/block/$device/queue/nr_requests
echo 0 > /sys/block/$device/queue/rotational
echo 1 > /sys/block/$device/queue/rq_affinity
;;
"hdd")
echo "设置为HDD优化参数"
echo cfq > /sys/block/$device/queue/scheduler
echo 128 > /sys/block/$device/queue/nr_requests
echo 1 > /sys/block/$device/queue/rotational
echo 2 > /sys/block/$device/queue/rq_affinity
;;
*)
echo "使用默认优化参数"
echo mq-deadline > /sys/block/$device/queue/scheduler
;;
esac
# 通用优化
echo 256 > /sys/block/$device/queue/read_ahead_kb
echo 0 > /sys/block/$device/queue/add_random
}
# 检测磁盘类型
detect_disk_type() {
local device=$1
if [ -f "/sys/block/$device/queue/rotational" ]; then
local rotational=$(cat "/sys/block/$device/queue/rotational")
if [ "$rotational" -eq 0 ]; then
echo "ssd"
else
echo "hdd"
fi
else
echo "unknown"
fi
}
# 优化所有磁盘
for device in $(lsblk -d -o NAME | grep -v NAME); do
device_type=$(detect_disk_type "$device")
optimize_disk_params "$device" "$device_type"
done
# 文件系统优化
echo -e "\n文件系统优化..."
# 优化ext4文件系统
if mount | grep -q "type ext4"; then
echo "优化ext4文件系统参数"
# 可以在fstab中添加noatime,nodiratime等挂载选项
fi
echo "磁盘优化完成"四、综合性能监控平台
1. 一体化监控脚本
<strong>#!/bin/bash</strong>
# comprehensive_monitor.sh
# 颜色定义
RED='3[0;31m'
GREEN='3[0;32m'
YELLOW='3[1;33m'
BLUE='3[0;34m'
NC='3[0m'
# 日志函数
log() {
echo -e "${GREEN}[$(date '+%Y-%m-%d %H:%M:%S')]${NC} $1"
}
warn() {
echo -e "${YELLOW}[警告]${NC} $1"
}
error() {
echo -e "${RED}[错误]${NC} $1"
}
# 性能检查函数
check_cpu() {
local cpu_idle=$(mpstat 1 1 | tail -1 | awk '{print $12}')
local cpu_usage=$(echo "100 - $cpu_idle" | bc)
if (( $(echo "$cpu_usage > 90" | bc -l) )); then
error "CPU使用率过高: ${cpu_usage}%"
return 1
elif (( $(echo "$cpu_usage > 70" | bc -l) )); then
warn "CPU使用率较高: ${cpu_usage}%"
return 2
else
log "CPU使用率正常: ${cpu_usage}%"
return 0
fi
}
check_memory() {
local mem_available=$(grep MemAvailable /proc/meminfo | awk '{print $2}')
local mem_total=$(grep MemTotal /proc/meminfo | awk '{print $2}')
local mem_usage_percent=$(echo "scale=2; ($mem_total - $mem_available) * 100 / $mem_total" | bc)
if (( $(echo "$mem_usage_percent > 90" | bc -l) )); then
error "内存使用率过高: ${mem_usage_percent}%"
return 1
elif (( $(echo "$mem_usage_percent > 80" | bc -l) )); then
warn "内存使用率较高: ${mem_usage_percent}%"
return 2
else
log "内存使用率正常: ${mem_usage_percent}%"
return 0
fi
}
check_disk() {
local disk_usage=$(df / | tail -1 | awk '{print $5}' | sed 's/%//')
if [ "$disk_usage" -gt 90 ]; then
error "磁盘使用率过高: ${disk_usage}%"
return 1
elif [ "$disk_usage" -gt 80 ]; then
warn "磁盘使用率较高: ${disk_usage}%"
return 2
else
log "磁盘使用率正常: ${disk_usage}%"
return 0
fi
}
check_io() {
local io_wait=$(mpstat 1 1 | tail -1 | awk '{print $6}')
if (( $(echo "$io_wait > 30" | bc -l) )); then
error "IO等待过高: ${io_wait}%"
return 1
elif (( $(echo "$io_wait > 20" | bc -l) )); then
warn "IO等待较高: ${io_wait}%"
return 2
else
log "IO等待正常: ${io_wait}%"
return 0
fi
}
# 生成报告
generate_report() {
echo -e "\n${BLUE}====== 系统性能报告 ======${NC}"
echo "生成时间: $(date)"
echo "主机名: $(hostname)"
check_cpu
check_memory
check_disk
check_io
echo -e "\n${BLUE}====== 系统基本信息 ======${NC}"
echo "系统版本: $(cat /etc/os-release | grep PRETTY_NAME | cut -d= -f2 | tr -d '\"')"
echo "内核版本: $(uname -r)"
echo "运行时间: $(uptime -p)"
echo "当前负载: $(uptime | awk -F'load average:' '{print $2}')"
}
# 主函数
main() {
local interval=${1:-300} # 默认5分钟检查一次
echo "启动综合性能监控,检查间隔: ${interval}秒"
while true; do
generate_report
echo -e "\n${YELLOW}下次检查在 ${interval} 秒后...${NC}"
sleep $interval
done
}
# 执行监控
main "$@"总结
Linux系统性能故障排查需要系统化的方法和专业的工具链。通过本文提供的监控脚本、分析工具和优化方案,运维团队可以快速定位内存泄漏、CPU爆满、磁盘IO瓶颈等常见问题。建议在生产环境中建立完善的监控体系,定期进行性能评估和优化调整。
© 版权声明
THE END












暂无评论内容